使用Ruby实现BigPipe
试想这样一个场景,一个经常访问的网站,每次打开它的页面都要要花费6 秒;同时另外一个网站提供了相似的服务,但响应时间只需3 秒,那么你会如何选择呢?数据表明,如果用户打开一个网站,等待3~4 秒还没有任何反应,他们会变得急躁,焦虑,抱怨,甚至关闭网页并且不再访问,这是非常糟糕的情况。所以,网页加载的速度十分重要,尤其对于拥有大量用户的大型网站,有着大量并发请求、海量数据等客观情况,速度就成了必须攻克的难题之一。
BigPipe的技术背景
2010 年初的时候,Facebook 的前端性能研究小组开始了他们的优化项目,经过了六个月的努力,成功的将个人空间主页面加载耗时由原来的5 秒减少为现在的2.5 秒。这是一个非常了不起的成就,也给用户来带来了很好的体验。在优化项目中,Facebook的高级研究科学家蒋长浩(Changhao Jiang)博士提出了一种新的页面加载技术,称之为Bigpipe。
传统的页面加载模型
首先,我们来看一个传统页面的加载流程。一个动态页面从用户请求开始到最终渲染结束大致分成以下几个步骤:
- 用户访问网页,浏览器发送一个HTTP请求到网络服务器
- 服务器解析这个请求,然后从存储层取得数据,经过一系列复杂的处理生成一个html文件内容,并在一个HTTP Response 中把它传送给客户端
- HTTP response 在网络中传输
- 浏览器解析这个Response ,创建一个DOM树,然后下载所需的CSS和JS文件
- 下载完CSS文件后,浏览器解析他们并且应用在相应的内容上
- 下载完JS后,浏览器解析和执行他们
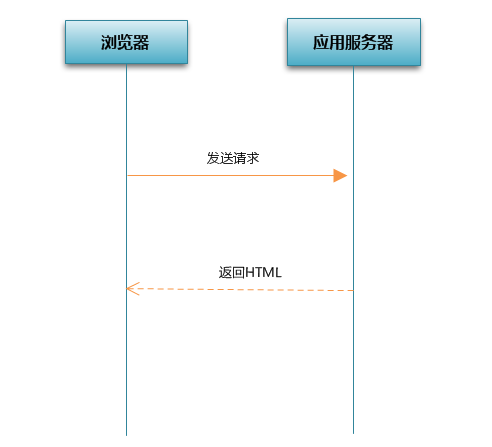
这种模式有明显的缺陷: 流程中的动作是按照顺序执行的,如果前面一个动作没结束,后面的动作就不能被执行。也就是说,浏览器在发送请求到收到回应这个过程中一直处于闲置状态。在用户看来,这个阶段浏览器一直显示一个空白页面;当浏览器加载并渲染内容的时候,服务器又处于闲置状态,时间和性能的浪费由此产生。

上图:现有的服务模型,横轴表示花费的时间。黄色表示在服务器的生成页面内容的时间,白色表示网络传输时间,蓝色表示在浏览器渲染页面的时间。可以看出,现有的模式造成很大的时间浪费。
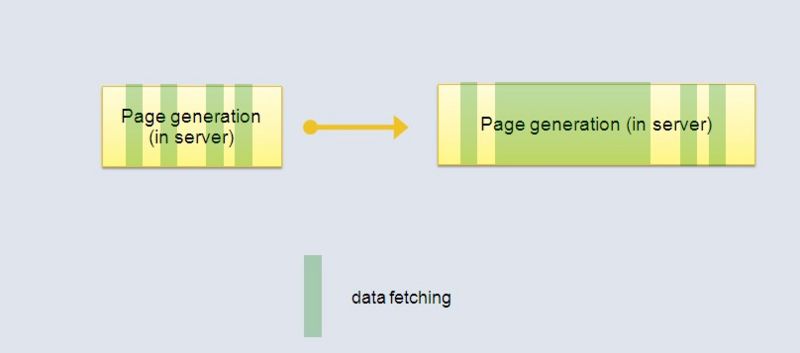
上图中绿色表示服务器从存储层取查数据花费的时间。在海量数据下,当执行一条很费时的查询语句时(如上图右侧),服务器就就阻塞在那 里没有其他操作,而浏览器更是得不到任何反馈。这会造成非常不友好的用户体验,用户不知道什么原因使他们等待很长时间。
使用Ajax
为了解决页面生成时间慢造成用户等待时间长的问题,有些人想出了使用Ajax技术分块加载内容的解决办法。即将网页的内容进行分区,首次请求时,服务器会返回整个网页的框架,然后浏览器解析并运行javascript,javascript向服务器发出XMLHttpRequest,获取区块的数据。服务器收到请求后进行处理,并返回区块数据,浏览器再次渲染。这个过程反复执行,直到所有需要显示的区块都被加载完。
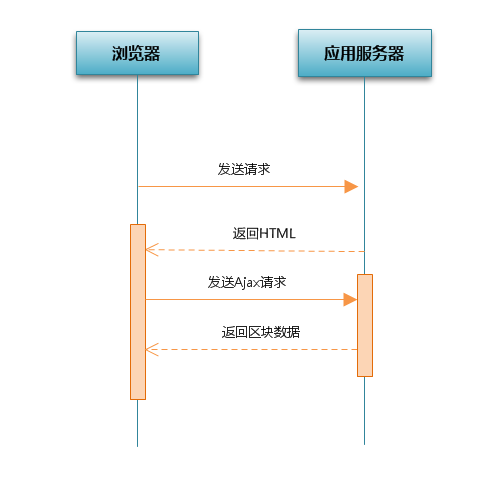
使用Ajax后虽然页面主体呈现时间缩短了,但是整个页面完全加载的时间反而会增加,因为每个Ajax请求都会有请求和响应的等待时间。使用Ajax还会产生副作用,那就是会增加浏览器发送的请求数。对于访问量很大的网站,这种做法会增加服务器的负担。
BigPipe的思想
为了解决上面的问题,BigPipe提出了分块的概念,并且将块在一个HTTP请求中发送给浏览器。即根据页面的内容,将整个页面划分成若干的区块--称为“pagelet”,服务器每完成一个pagelet的处理,都会立即将其通过当前的HTTP连接发送给浏览器,而不再需要等待浏览器端通过XMLHttpRequest发送新的请求。浏览器收到新的pagelet后,会立刻按照需求处理内容,加载相应的CSS和Javascript,并进行渲染。浏览器处理当前pagelet的同时,服务器在生成新的pagelet。众多pagelet加载的不同阶段像流水线一样在浏览器和服务器上执行,这样就做到了浏览器和服务器的并行化,从而达到重叠服务器端运行时间和浏览器端运行时间的目的。使用BigPipe 不仅可以节省时间,使加载的时间缩短,而且可以同过pagelet的分步输出,使一部分的页面内容更快的输出,从而获得更好的用户体验。BigPipe 中,用户提出页面访问请求后,页面的完整加载流程如下:
- Request parsing:服务器解析和检查http request
- Datafetching:服务器从存储层获取数据
- Markup generation:服务器生成html 标记
- Network transport : 网络传输response
- CSS downloading:浏览器下载CSS
- DOM tree construction and CSS styling:浏览器生成DOM 树,并且使用CSS
- JavaScript downloading: 浏览器下载页面引用的JS 文件
- JavaScript execution: 浏览器执行页面JS代码
虽然这个流程跟上面的流程并无实质区别,但这仅仅是一个pagelet的完整流程,如果有多个pagelet,流程就不一样了:
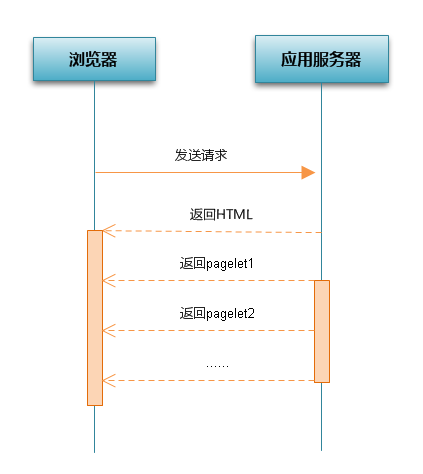
BigPipe打破了原有的页面加载顺序,虽然每个pagelet的执行时间并没有缩短,但是将众多的pagelet叠加起来,总的运行时间就会大大缩短:
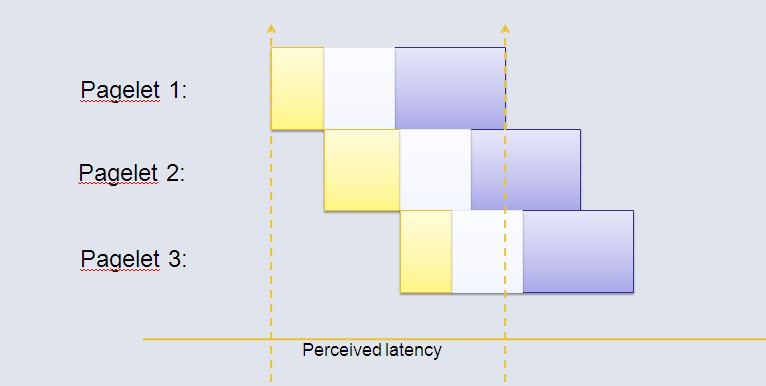
BigPipe的实现原理
了解了BigPipe的思想之后,我们来看看它的实现原理。当浏览器向服务器发起请求后,服务器接受请求,并对其进行检查,如果请求有效,服务器会立刻返回一个HTTP response给浏览器,其内容是一段标准的HTML代码,包括<head>和<body>标签。这段HTML代码只是页面的基本框架,服务器不应该做一些耗时较长的操作,以便内容能够快速的发送给浏览器。<head>中包括BigPipe依赖的JS和CSS,浏览器收到这个响应后就会立刻开始请求并处理JS和CSS。HTML框架的<body>是未关闭,方便后面的pagelet传输。其中还包括pagelet的占位符,例如:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<style type="text/css">
.pagelat {
margin: 20px;
border: 1px dotted #CCC;
}
.pagelat h2 {
background: #999;
color: #FFF;
margin:0;
line-height: 2em;
}
</style>
<script type="text/javascript">
var Bigpipe = {
puts: function(id,content){
console.log(id,content);
var dom = document.getElementById(id);
console.log(dom);
if(dom) dom.innerHTML = content;
}
};
</script>
</head>
<body>
<div class="pagelat">
<h2>区域1</h2>
<p id="pagelat1"></p>
</div>
<div class="pagelat">
<h2>区域2</h2>
<p id="pagelat2"></p>
</div>
服务器处理好pagelet后,会将类似下面的代码发送给浏览器:
<script>Bigpipe.puts("pagelat1","这是第一块")</script>
而后浏览器会处理这个<scritp>并重新渲染页面。这样,前端对pagelet的发送顺序并没有特殊的要求,谁先收到谁先被处理,因此也解决了传统模型中前端对后端在数据发送顺序上的依赖问题。
使用Ruby实现BigPipe
晚上目前还很少见使用ruby实现BigPipe的方案,只有一个bigpipe-rails的gem也是很久前的未更新项目了。这里我使用Sinatra框架配合EventMachine简单的实现了BigPipe。首先,先看一下使用传统的模型的情况:
views/normal.erb
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<style type="text/css">
.pagelat {
margin: 20px;
border: 1px dotted #CCC;
}
.pagelat h2 {
background: #999;
color: #FFF;
margin:0;
line-height: 2em;
}
</style>
</head>
<body>
<div class="pagelat">
<h2>区域1</h2>
<p id="pagelat1"><%=@pagelat1%></p>
</div>
<div class="pagelat">
<h2>区域2</h2>
<p id="pagelat2"><%=@pagelat2%></p>
</div>
</body>
</html>
main.rb
get '/' do
sleep 2
@pagelat1 = "这是第一块"
sleep 5
@pagelat2 = "这是第二块"
erb(:normal)
end
这里使用了俩个sleep来模拟实际环境中的慢速IO和复杂处理。两次执行分别等待2秒和5秒。这个页面加载时间在7秒以上:
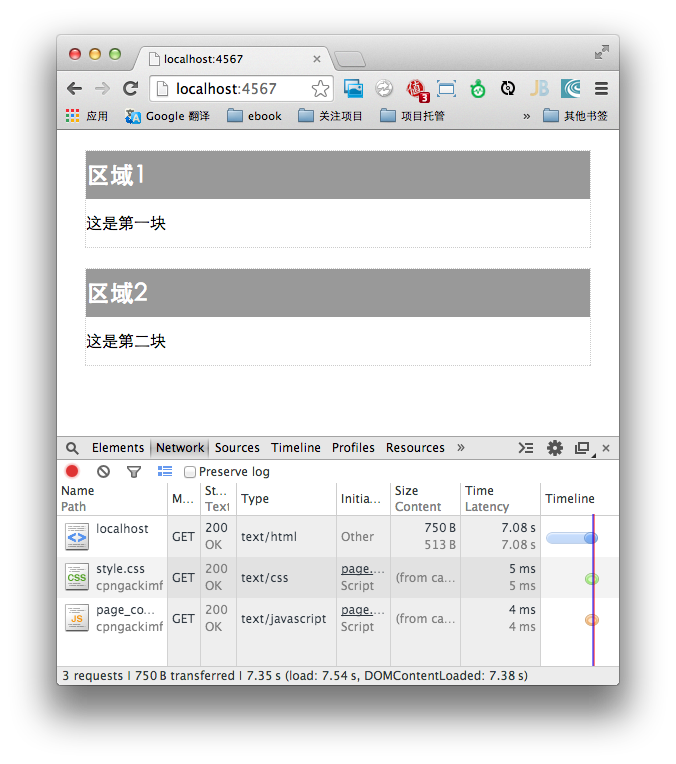
要实现BigPipe,首先要解决的是如何在一次HTTP请求中分次传输数据的问题。解决这个问题,需要使用HTTP 1.1协议中的分块传输机制(Chunked transfer encoding)。
一般的HTTP协议要求消息一次传输,并且服务器需要首先返回Content-Length头告知浏览器传输的数据长度。使用分块传输机制则可以不首先返回Content-Length头,而是发送一个Transfer-Encoding: chunked的头告诉浏览器要开启分块传输。分块传输的消息体也不是一次性发送给浏览器的,它是由数量未定的块组成并分多次传输。
分块传输的消息以最后一个大小为0的块为结束标记。每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)。
最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。
消息最后以CRLF结尾。例如如下的形式:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
为了实现这样的协议,需要将相关的代码封装成Sinatra的helper方便后面调用:
module Sinatra
module Helpers
class Stream
def each(&front)
@front = front
callback do
@front.call("0\r\n\r\n")
end
@scheduler.defer do
begin
@back.call(self)
rescue Exception => e
@scheduler.schedule { raise e }
end
close unless @keep_open
end
end
def <<(data)
@scheduler.schedule do
size = data.to_s.bytesize
@front.call([size.to_s(16), "\r\n", data.to_s, "\r\n"].join)
end
self
end
end
end
end
然后再准备一个BigPipe的页面框架:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<style type="text/css">
.pagelat {
margin: 20px;
border: 1px dotted #CCC;
}
.pagelat h2 {
background: #999;
color: #FFF;
margin:0;
line-height: 2em;
}
</style>
<script type="text/javascript">
var Bigpipe = {
puts: function(id,content){
console.log(id,content);
var dom = document.getElementById(id);
console.log(dom);
if(dom) dom.innerHTML = content;
}
};
</script>
</head>
<body>
<div class="pagelat">
<h2>区域1</h2>
<p id="pagelat1"></p>
</div>
<div class="pagelat">
<h2>区域2</h2>
<p id="pagelat2"></p>
</div>
然后在main.rb中添加相应的逻辑
main.rb
get '/chunked' do
response['Transfer-Encoding'] = 'chunked'
stream :keep_open do |out|
out << erb(:bigpipe)
sleep 2
out << '<script>Bigpipe.puts("pagelat1","这是第一块")</script>'
sleep 5
out << '<script>Bigpipe.puts("pagelat2","这是第二块")</script>'
out.close
end
end
访问这个路径后会发现,两个区块的内容依次被显示出来了,但由于服务器端还是顺序执行,因此总时长并没有缩短,依旧是7秒钟:
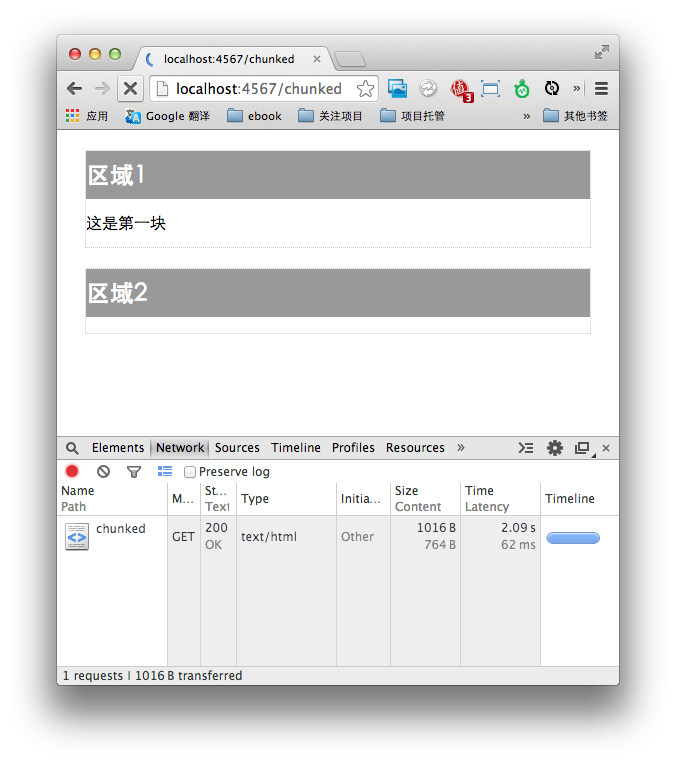
到目前为止,BigPipe还没有真正实现。现在还需要在服务器端实现一个并发操作——并发去读取和处理数据。Ruby实现并发有很多种方法。这里我使用了EventMachine的defer方法,将模拟的费时操作放入defer的块中:
main.rb
get '/bigpipe' do
response['Transfer-Encoding'] = 'chunked'
stream :keep_open do |out|
queue = []
#当两个任务都执行完毕,关闭连接。
callback = proc do |result|
queue << 1
out << result
out.close if queue.length > 1
end
out << erb(:bigpipe)
EM.epoll
EM.run do
EM.defer(proc{
sleep 2
'<script>Bigpipe.puts("pagelat1","这是第一块")</script>'
},callback)
EM.defer(proc {
sleep 5
'<script>Bigpipe.puts("pagelat2","这是第二块")</script>'
},callback)
end
end
end
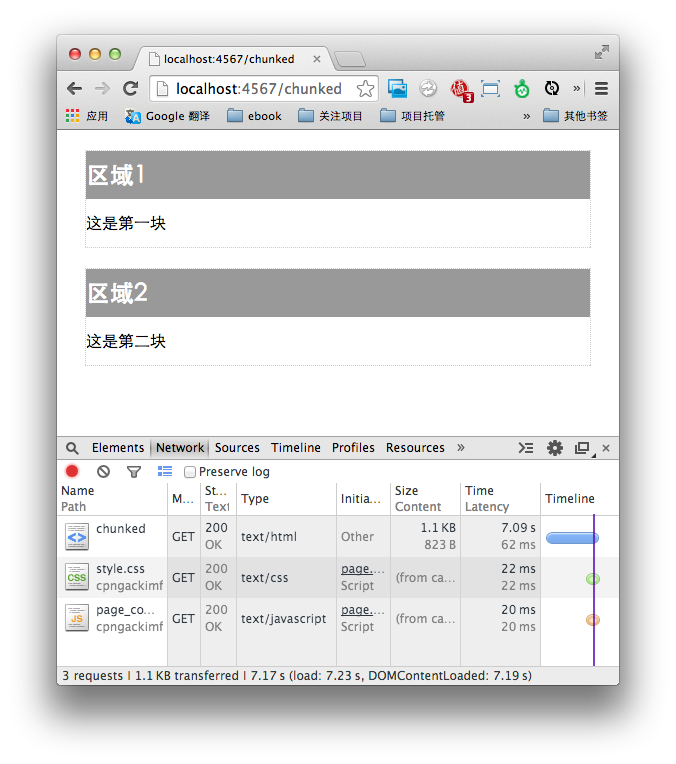
代码中使用了一个数组来检测是否所有任务都已完成。每完成一个任务,程序向数组queue中写入一个值,当数组中有两个元素时,程序判定所有任务都结束,然后关闭当前的链接。现在打开浏览器,访问/bigpipe,就会发现,整体响应时间由原来的7秒,变成了5秒。BigPipe成功减少了2秒的响应时间:
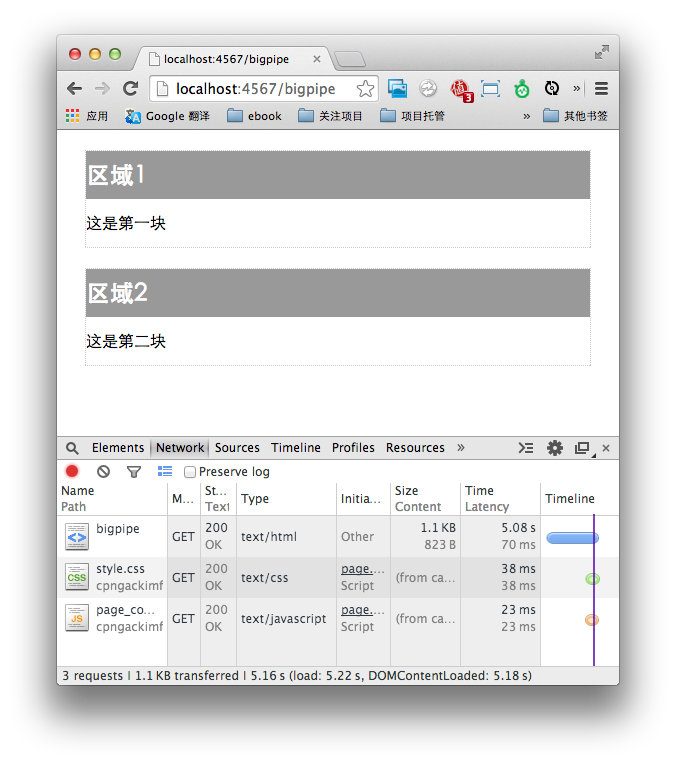
上面的例子只是使用最简单的方法实现了基本的BigPipe,实际运用中还要进一步的加工和完善。欢迎大家来吐槽指正。
在项目中使用BigPipe会产生的问题
一个新技术有利必然有弊,BigPipe在优化用户体验的同时又会产生哪些问题呢?目前已知可能会产生如下两个问题:
- 搜索引擎无法抓取完整页面,从而产生一些问题
- 由于前端页面需要分块传输,会增加整个程序的复杂度,对开发团队的要求较高。
对于第一个问题,目前采取的解决办法是:服务器端检测请求头,如果是搜索引擎的蜘蛛,则不使用BigPipe技术而是直接返回完整的文档。对于第二个问题:我觉得合理使用是不错的解决方案。一些简单的页面就无需使用BigPipe技术了。
欢迎转载,请注明出处,谢谢